PostgreSQL常用命令学习
主要是常用的一些系统操作的指令,和DDL和DML语句无关
主要是常用的一些系统操作的指令,和DDL和DML语句无关
当你打开计算机电源,计算机会首先加载BIOS信息,BIOS信息是如此的重要,以至于计算机必须在最开始就找到它。这是因为BIOS中包含了CPU的相关信息、设备启动顺序信息、硬盘信息、内存信息、时钟信息、PnP特性等等。在此之后,计算机心里就有谱了,知道应该去读取哪个硬件设备了。
众所周知,硬盘上第0磁道第一个扇区被称为MBR,也就是Master Boot Record,即主引导记录,它的大小是512字节,别看地方不大,可里面却存放了预启动信息、分区表信息。
系统找到BIOS所指定的硬盘的MBR后,就会将其复制到0×7c00地址所在的物理内存中。其实被复制到物理内存的内容就是Boot Loader,而具体到你的电脑,那就是lilo或者grub了。
Boot Loader 就是在操作系统内核运行之前运行的一段小程序。通过这段小程序,我们可以初始化硬件设备、建立内存空间的映射图,从而将系统的软硬件环境带到一个合适的状态,以便为最终调用操作系统内核做好一切准备。
Boot Loader有若干种,其中Grub、Lilo和spfdisk是常见的Loader。
我们以Grub为例来讲解吧,毕竟用lilo和spfdisk的人并不多。
系统读取内存中的grub配置信息(一般为menu.lst或grub.lst),并依照此配置信息来启动不同的操作系统。
根据grub设定的内核映像所在路径,系统读取内存映像,并进行解压缩操作。此时,屏幕一般会输出“Uncompressing Linux”的提示。当解压缩内核完成后,屏幕输出“OK, booting the kernel”。
系统将解压后的内核放置在内存之中,并调用start_kernel()函数来启动一系列的初始化函数并初始化各种设备,完成Linux核心环境的建立。至此,Linux内核已经建立起来了,基于Linux的程序应该可以正常运行了。
内核被加载后,第一个运行的程序便是/sbin/init,该文件会读取/etc/inittab文件,并依据此文件来进行初始化工作。
其实/etc/inittab文件最主要的作用就是设定Linux的运行等级,其设定形式是“:id:5:initdefault:”,这就表明Linux需要运行在等级5上。Linux的运行等级设定如下:
0:关机
1:单用户模式
2:无网络支持的多用户模式
3:有网络支持的多用户模式
4:保留,未使用
5:有网络支持有X-Window支持的多用户模式
6:重新引导系统,即重启
关于/etc/inittab文件的学问,其实还有很多
在设定了运行等级后,Linux系统执行的第一个用户层文件就是/etc/rc.d/rc.sysinit脚本程序,它做的工作非常多,包括设定PATH、设定网络配置(/etc/sysconfig/network)、启动swap分区、设定/proc等等。如果你有兴趣,可以到/etc/rc.d中查看一下rc.sysinit文件,里面的脚本够你看几天的
具体是依据/etc/modules.conf文件或/etc/modules.d目录下的文件来装载内核模块。
根据运行级别的不同,系统会运行rc0.d到rc6.d中的相应的脚本程序,来完成相应的初始化工作和启动相应的服务。
你如果打开了此文件,里面有一句话,读过之后,你就会对此命令的作用一目了然:
1 | # This script will be executed *after* all the other init scripts. |
rc.local就是在一切初始化工作后,Linux留给用户进行个性化的地方。你可以把你想设置和启动的东西放到这里。
此时,系统已经进入到了等待用户输入username和password的时候了,你已经可以用自己的帐号登入系统了。:)
原文链接:https://blog.csdn.net/wangzhen209/article/details/72377317
先分区再格式化 —— 分区完成后可以格式化不同的文件系统
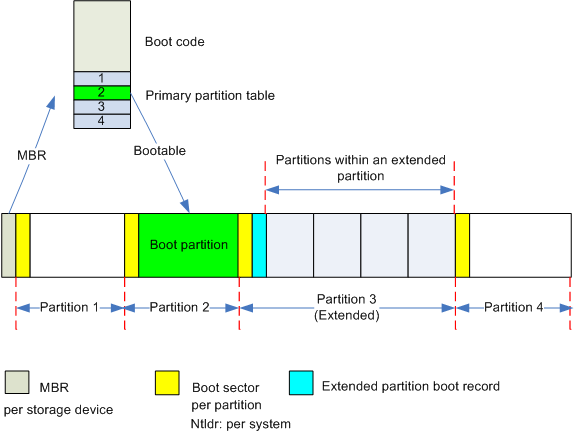
硬盘的分区主要分为基本分区(primary partion,也可以叫主分区)和扩展分区(extension partion)两种
基本分区和扩展分区的数目之和不能大于四个 —— 分区表上最多只能记录四条记录
基本分区可以马上被使用但不能再分区
扩展分区必须再进行分区后才能使用,也就是说它必须还要进行二次分区。那么由扩展分区再分下去的是什么呢?它就是逻辑分区(logical partion),况且逻辑分区没有数量上限制。
对red hat linux用户来说无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构。red hat linux中每个分区都是用来组成整个文件系统的一部分,因为它采用了一种叫“载入”的处理方法,它的整个文件系统中包含了一整套的文件和目录,且将一个 分区和一个目录联系起来。这时要载入的一个分区将使它的存储空间在一个目录下获得。
对red hat linux来说,你可以把系统文件分几个区来装(必须要说明载入点),也可以就装在同一个分区中(载入点是“/”)
带有硬盘分区信息
分区名的前两个字母标明分区所在设备的类型,通常是hd(IDE磁盘)或sd(SCSI磁盘)
最后的数字代表分区,前四个分区是用数字1到4排列的,记录主分区和扩展分区的信息,逻辑分区从5开始
硬盘有数个盘片,每隔盘片有两个面,每个面一个磁头
盘片被划分为多个扇形区域即扇区
同一盘片不同半径的同心圆为磁道
不同盘片相同半径构成的圆柱面即柱面
存储容量 = 磁头数 x 磁道(柱面)数 x 每道扇区数 x 每扇区字节数
信息记录可以表示为:
xx磁道(柱面), xx磁头, xx扇区
MBR位于硬盘第一个物理扇区(绝对扇区)柱面0,磁头0,扇区1处
MBR中包含硬盘的主引导程序和硬盘分区表
至少两个分区
/ 分区
SWAP分区
https://www.linuxidc.com/Linux/2014-03/97502.htm
https://blog.csdn.net/jackyu651/article/details/53070607
https://blog.csdn.net/huaweitman/article/details/51637054
/ Linux文件系统的入口,最高级目录
/usr/bin、/bin : 存放所有用户可以执行的命令
/usr/sbin、/sbin : 存放只有root可以执行的命令
/home : 用户缺省的宿主目录
/proc : 虚拟文件系统,存放当前进程信息
/dev : 存放设备文件,因为分区在硬盘上,硬盘是设备,所以分区信息全部在/dev下
/lib : 存放系统程序运行所需的共享库
/lost+found : 存放系统出错的检查结果
/tmp : 存放临时文件
/etc : 存储系统的配置
/var : 包含经常发生变动的文件,如日志文件、计划任务等,存放临时文件
/usr : 存放所有命令、库、手册等
/usr/local : 软件安装的目录
/boot : 内核文件及自举程序文件保存位置,存放启动文件 128M足够
/mnt : 临时系统文件的安装点
虚拟内存,配置为实际物理内存的两倍
本文转自网络,侵删。 原文地址https://blog.csdn.net/bv1315008634/article/details/53327002
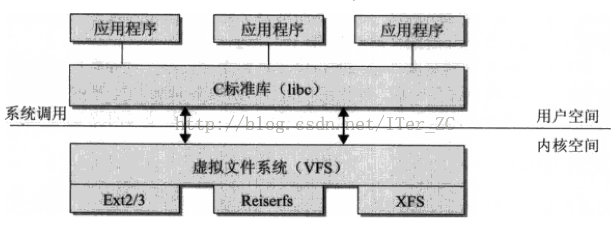
Linux文件管理从用户的层面介绍了Linux管理文件的方式。Linux有一个树状结构来组织文件。树的顶端为根目录(/),节点为目录,而末端的叶子为包含数据的文件。当我们给出一个文件的完整路径时,我们从根目录出发,经过沿途各个目录,最终到达文件。
我们可以对文件进行许多操作,比如打开和读写。在Linux文件管理相关命令中,我们看到许多对文件进行操作的命令。它们大都基于对文件的打开和读写操作。比如cat可以打开文件,读取数据,最后在终端显示:
1 | cat test.txt |
对于Linux下的程序员来说,了解文件系统的底层组织方式,是深入进行系统编程所必备的。即使是普通的Linux用户,也可以根据相关的内容,设计出更好的系统维护方案。
操作系统的很多核心组件都是相互关联的,比如虚拟内存管理,物理内存管理,文件系统,缓存系统,IO,设备管理等等,都要放在一起来看才能从整体上理解各个模块到底是如何交互和工作的。这个系列的目的也就是从整体上来理解计算机底层硬件和操作系统的一些重要的组件是如何工作的,从而来指导应用层的开发。这篇讲讲文件系统的重要概念,为后面的IO系统做铺垫。
文件系统主要有三类
一个操作系统可以支持多种底层不同的文件系统,为了给内核和用户进程提供统一的文件系统视图,Linux在用户进程和底层文件系统之间加入了一个抽象层,即虚拟文件系统(Virtual File System, VFS),进程所有的文件操作都通过VFS,由VFS来适配各种底层不同的文件系统,完成实际的文件操作。
通俗的说,VFS就是定义了一个通用文件系统的接口层和适配层,一方面为用户进程提供了一组统一的访问文件,目录和其他对象的统一方法,另一方面又要和不同的底层文件系统进行适配。
VFS采用了面向对象的思路来设计它的核心组件,只是VFS是用C写的,没有对象的语法,只能用struct来表示。我们按照面向对象的思路来理解VFS。
它有4个主要的对象类型:
VFS给每个对象都定义了一组操作对象(函数指针),给出了这些操作的默认实现,底层不同的文件系统可以重写(override)VFS的操作函数来给出自己的具体操作实现,也可以复用VFS的默认实现。实际情况是底层文件系统部分操作由自己单独实现,部分复用了VFS的默认实现。
操作对象有:
文件系统说白了就是文件内容和存储系统对应的块的映射关系,是来管理文件的存储的。inode-block结构把文件分为了两部分,inode表示元数据,block表示存储文件内容的具体的逻辑块。VFS没有用单独的对象来表示block,block的属性在超级块和inode块中包含了。
文件系统的最终目的是把大量数据有组织的放入持久性(persistant)的存储设备中,比如硬盘和磁盘。这些存储设备与内存不同。它们的存储能力具有持久性,不会因为断电而消失;存储量大,但读取速度慢。
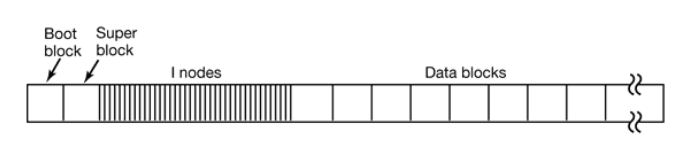
观察常见存储设备。最开始的区域是MBR,用于Linux开机启动(参考Linux开机启动)。剩余的空间可能分成数个分区(partition)。每个分区有一个相关的分区表(Partition table),记录分区的相关信息。这个分区表是储存在分区之外的。分区表说明了对应分区的起始位置和分区的大小
我们在Windows系统常常看到C分区、D分区等。Linux系统下也可以有多个分区,但都被挂载在同一个文件系统树上。
数据被存入到某个分区中。一个典型的Linux分区(partition)包含有下面各个部分:
分区的第一个部分是启动区(Boot block),它主要是为计算机开机服务的。Linux开机启动后,会首先载入MBR,随后MBR从某个硬盘的启动区加载程序。该程序负责进一步的操作系统的加载和启动。为了方便管理,即使某个分区中没有安装操作系统,Linux也会在该分区预留启动区。
启动区之后的是超级区(Super block)。它存储有文件系统的相关信息,包括文件系统的类型,inode的数目,数据块的数目。
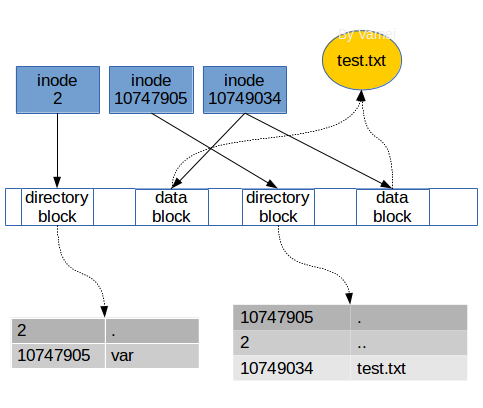
随后是多个inodes,它们是实现文件存储的关键。在Linux系统中,一个文件可以分成几个数据块存储,就好像是分散在各地的龙珠一样。为了顺利的收集齐龙珠,我们需要一个“雷达”的指引:该文件对应的inode。每个文件对应一个inode。这个inode中包含多个指针,指向属于该文件各个数据块。当操作系统需要读取文件时,只需要对应inode的”地图”,收集起分散的数据块,就可以收获我们的文件了。
最后一部分,就是真正储存数据的数据块们(data blocks)了。
上面我们看到了存储设备的宏观结构。我们要深入到分区的结构,特别是文件在分区中的存储方式。
文件是文件系统对数据的分割单元。文件系统用目录来组织文件,赋予文件以上下分级的结构。在硬盘上实现这一分级结构的关键,是使用inode来虚拟普通文件和目录文件对象。
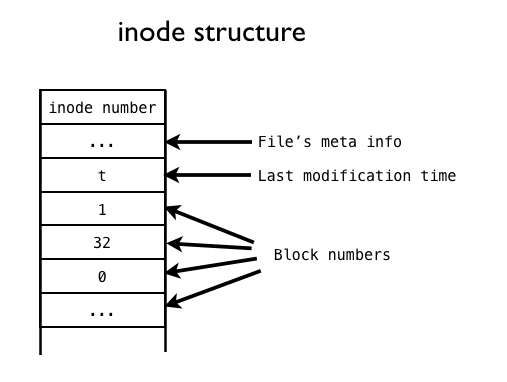
在Linux文件管理中,我们知道,一个文件除了自身的数据之外,还有一个附属信息,即文件的元数据(metadata)。这个元数据用于记录文件的许多信息,比如文件大小,拥有人,所属的组,修改日期等等。元数据并不包含在文件的数据中,而是由操作系统维护的。事实上,这个所谓的元数据就包含在inode中。我们可以用$ls -l filename来查看这些元数据。正如我们上面看到的,inode所占据的区域与数据块的区域不同。每个inode有一个唯一的整数编号(inode number)表示。
在保存元数据,inode是“文件”从抽象到具体的关键。正如上一节中提到的,inode储存由一些指针,这些指针指向存储设备中的一些数据块,文件的内容就储存在这些数据块中。当Linux想要打开一个文件时,只需要找到文件对应的inode,然后沿着指针,将所有的数据块收集起来,就可以在内存中组成一个文件的数据了。
数据块在1, 32, 0, …
inode并不是组织文件的唯一方式。最简单的组织文件的方法,是把文件依次顺序的放入存储设备,DVD就采取了类似的方式。但如果有删除操作,删除造成的空余空间夹杂在正常文件之间,很难利用和管理。
复杂的方式可以使用链表,每个数据块都有一个指针,指向属于同一文件的下一个数据块。这样的好处是可以利用零散的空余空间,坏处是对文件的操作必须按照线性方式进行。如果想随机存取,那么必须遍历链表,直到目标位置。由于这一遍历不是在内存进行,所以速度很慢。
FAT系统是将上面链表的指针取出,放入到内存的一个数组中。这样,FAT可以根据内存的索引,迅速的找到一个文件。这样做的主要问题是,索引数组的大小与数据块的总数相同。因此,存储设备很大的话,这个索引数组会比较大。
inode既可以充分利用空间,在内存占据空间不与存储设备相关,解决了上面的问题。但inode也有自己的问题。每个inode能够存储的数据块指针总数是固定的。如果一个文件需要的数据块超过这一总数,inode需要额外的空间来存储多出来的指针。
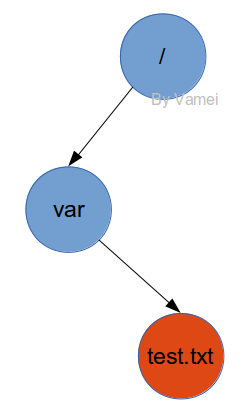
在Linux中,我们通过解析路径,根据沿途的目录文件来找到某个文件。目录中的条目除了所包含的文件名,还有对应的inode编号。当我们输入$cat /var/test.txt时,Linux将在根目录文件中找到var这个目录文件的inode编号,然后根据inode合成var的数据。随后,根据var中的记录,找到text.txt的inode编号,沿着inode中的指针,收集数据块,合成text.txt的数据。整个过程中,我们参考了三个inode:根目录文件,var目录文件,text.txt文件的inodes。
在Linux下,可以使用$stat filename,来查询某个文件对应的inode编号。
在存储设备中实际上存储为:
当我们读取一个文件时,实际上是在目录中找到了这个文件的inode编号,然后根据inode的指针,把数据块组合起来,放入内存供进一步的处理。当我们写入一个文件时,是分配一个空白inode给该文件,将其inode编号记入该文件所属的目录,然后选取空白的数据块,让inode的指针指像这些数据块,并放入内存中的数据。
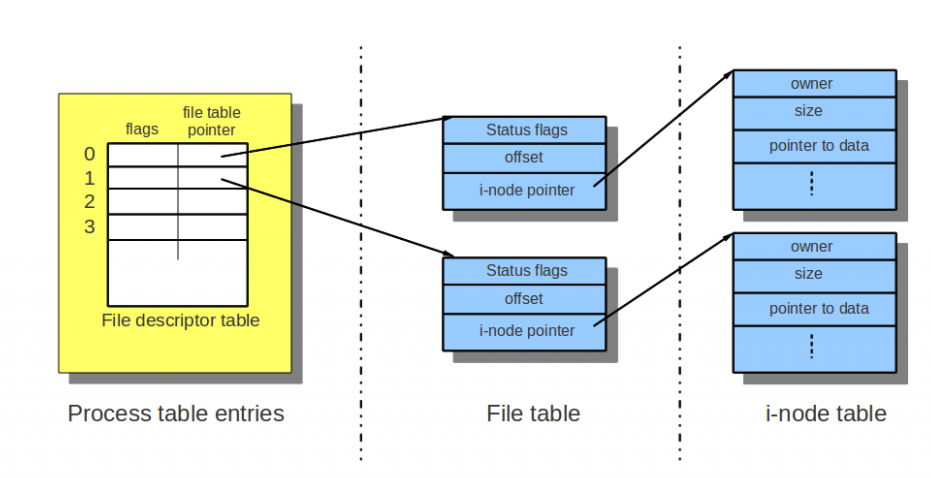
在Linux的进程中,当我们打开一个文件时,返回的是一个文件描述符。这个文件描述符是一个数组的下标,对应数组元素为一个指针。有趣的是,这个指针并没有直接指向文件的inode,而是指向了一个文件表格,再通过该表格,指向加载到内存中的目标文件的inode。如下图,一个进程打开了两个文件。
可以看到,每个文件表格中记录了文件打开的状态(status flags),比如只读,写入等,还记录了每个文件的当前读写位置(offset)。当有两个进程打开同一个文件时,可以有两个文件表格,每个文件表格对应的打开状态和当前位置不同,从而支持一些文件共享的操作,比如同时读取。
要注意的是进程fork之后的情况,子进程将只复制文件描述符的数组,而和父进程共享内核维护的文件表格和inode。此时要特别小心程序的编写。
Web服务器也称为WWW服务器、HTTP服务器,其主要功能是提供网上信息浏览服务。
Unix和Linux平台下常用的Web服务器有以下几种:
其中应用最广泛的是Apache。
嗯,但是我们这篇文章的主角是Nginx,所以如果有同学想了解Apache的话,可以去自己查询相关资料。
Nginx是俄罗斯人Igor Sysoev编写的一款高性能的HTTP和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。于2004年10月4日发布第一个公开版本1.0,开源协议是类BSD许可协议,目前最新版本是1.15.0(2018-06-05发布)
官方测试Nginx能够支持5万并发连接,在实际生产环境中可以支撑2~4万并发连接数。这得益于Nginx使用了最新的epoll(Linux2.6内核)和kqueue(freebsd)网络I/O模型.
开源软件,可以免费使用,并且可以用于商业用途
能够根据域名、URL的不同,将HTTP请求分到不同的后端服务器群组
如果Nginx Proxy后端的某个Web服务器宕机了,不会影响前端访问
支持GZIP压缩,可以添加浏览器本地缓存的Header头
用于反向代理,宕机的概率微乎其微
可以在不间断服务的情况下对软件版本进行升级
pcre是一个正则表达式库,让nginx支持rewrite需要安装这个库。
https://ftp.pcre.org/pub/pcre/
在CentOS安装软件的时候,可能缺少一部分支持库,而报错。这里首先安装系统常用的支持库。那么在安装的时候就会减少很多的错误的出现。
1 | # yum install -y gcc gdb strace gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel ncurses ncurses-devel curl curl-devel e2fsprogs patch e2fsprogs-devel krb5-devel libidn libidn-devel openldap-devel nss_ldap openldap-clients openldap-servers libevent-devel libevent uuid-devel uuid mysql-devel |
检查是否安装了g++、gcc。rpm -qa | grep gcc 之后需要出现3个包如下图所示。

如果没有出现。需要安装g++、gcc。
1 | # yum install gcc-c++ |
1 | # cd /usr/local/soft/pcre |
1 | # cd pcre |
1 | # make |
1 | # make install |
1 | # rpm -qa | grep zlib-devel |
如果未安装,则使用yum进行安装
http://nginx.org/en/download.html
下载稳定版本,不要下载最新版本
1 | # tar -zxvf nginx-1.14.0.tar.gz |
将软件安装在/usr/local/webserver目录下
1 | # cd nginx-1.14.0 |
1 | # make |
1 | # cd /usr/local/webserver/nginx/sbin |
显示以下内容表示安装成功
1 | nginx: the configuration file /usr/local/webserver/nginx/conf/nginx.conf syntax is ok |
1 | <!--Redis--> |
1 | # REDIS (RedisProperties) |
data-redis在进行存储时,key和value默认使用了基于JDK的序列化方式(JdkSerializationRedisSerializer),在使用连接工具查看时看到的都是编码后的信息,不方便查看,所以需要更改默认的序列化方式。此处对key值的序列化使用自定义的String序列化器(data-redis也提供了一个基于String的序列化器,但是该序列化器的泛型是String类型的,不能传入其他类型的值,所以基于官方提供的String序列化器再重写一个泛型为Object的序列化器),对value使用基于FastJson的序列化器(FastJson也提供了一个序列化器,可以使用该序列化器,也可以仿照该序列化器自定义一个序列化器)
1 | public class StringRedisSerializer implements RedisSerializer<Object> { |
我这里用了官方提供的FastJSON序列化器,如果想自定义的话,可以参考以下代码:
1 | public class FastJsonRedisSerializer<T> implements RedisSerializer<T> { |
1 |
|
在pom.xml中添加spring-session-data-redis依赖
1 | <!-- Session共享 --> |
1 |
|
注意:maxInactiveIntervalInSeconds字段用来设置Session失效时间,使用Redis Session之后,原SpringBoot的server.session.timeout属性不再生效
1 |
|
将上述配置和代码写入到两个不同的项目中,然后访问http://127.0.0.1:8080/uid和http://127.0.0.1:8081/uid,返回的sessionId一致:
1 | 71f3099c-dcc0-4445-8d5e-57ef96d84412 |
通过Redis客户端连接可以看到:
1 | 127.0.0.1:6379> keys * |
在pom.xml中添加spring-boot-starter-actuator依赖
1 | <dependency> |
如果只添加actuator依赖,用户可以直接访问监控系统,而不需要权限认证,有安全风险。所以,为了安全性考虑,需要添加spring-boot-start-security依赖。
1 | <dependency> |
添加之后,用户访问监控页面的时候就会跳转到监控的登录页面,输入用户名和密码之后才能进入到监控界面。
在spring-boot-starter-web中用jetty替代tomcat
在spring-boot-starter-web移除现有的依赖项,并把下面的配置加到pom中
1 | <dependency> |
在开发调试阶段,可以配置SpringBoot的热启动,代码修改后实时更新,不需要重新启动项目。
在pom.xml中添加依赖。
1 | <dependencies> |
到此处,Eclipse已经能够自动编译了
idea比较特殊,需要设置自动编译
File->Settings-> Build-Execution-Deployment -> Compiler,勾选 Build Project Automatically.

组合键Shift+Ctrl+A打开配置面板,找到Registry…,点击

找到compiler.automake.allow.when.app.running,勾选,然后退出。

某些情况下,自动编辑可能不会生效,如果碰到这种情况,可以使用Ctrl + F9手动编译,不需要去重启服务。